선형 회귀의 문제는 답 또는 성질이 정해져 있는 데이터들을 바탕으로 실제의 값을 예측하는 문제입니다. 쉬운 예제로는 어떠한 지역에서의 땅 크기(Size) 및 집 값(Price)의 데이터가 주어졌을 때 이 데이터를 바탕으로 1350의 땅 크기는 집값이 얼마인지를 예측하는 문제가 되겠습니다. 이러한 선형 회귀의 문제는 전 포스트에서 언급한 Supervised Learning (지도 학습)의 한 영역입니다.
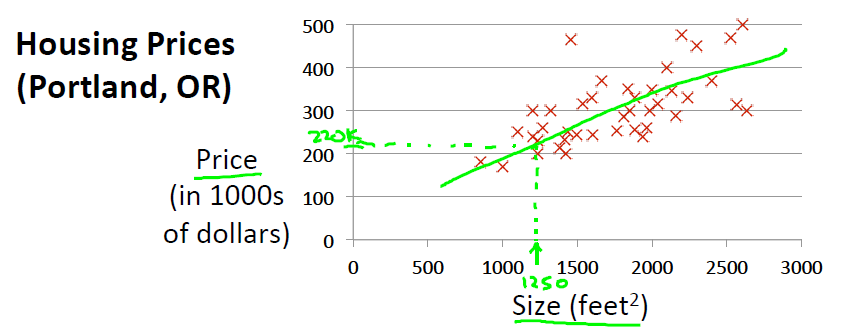
예측을 하기 위해서는 학습을 해야합니다. 학습을 위해서는 우선 학습 데이터 (Training Data)가 필요합니다. 위의 예제에서의 학습 데이터는 바로 하단과 같이 땅 크기와 집값이 1:1로 대응되어 나열된 데이터(표)가 되겠습니다.
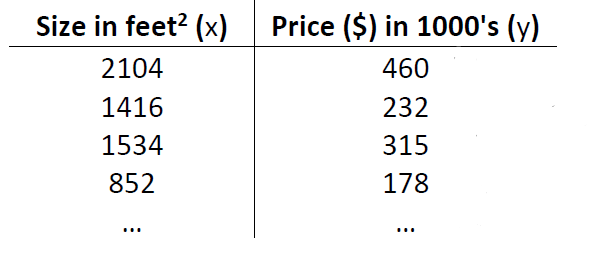
여기서 X와 Y가 있는데 X는 입력 변수를 의미하며 Y는 출력 변수를 의미합니다. 입력 변수는 흔히 특징(Feature)이라고 부릅니다. 그리고 출력(Target) 변수는 목표 변수라고 부릅니다. 여기서 X와 Y는 우리가 1350의 땅 크기에서 집값은 얼마일까라고 추측하는 문제이니 X는 1350이 되겠으며 Y는 그에 해당되는 집값이 되겠습니다.
예측을 위해서는 일종의 모델이 필요합니다.
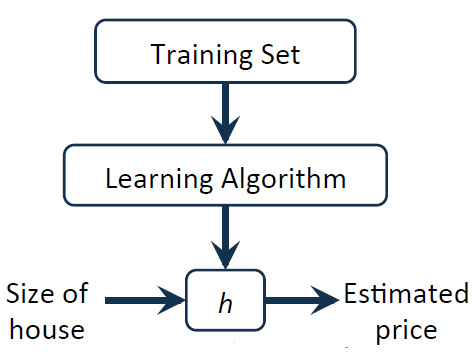
학습데이터를 이용하여 학습 알고리즘에 넣어서 실행을 하여 h를 얻게 되는데 해당 h 박스에 우리가 궁금해하는 입력 X(1350의 땅 크기)가 들어오면 예측되는 값으로 출력해주는 역할을 하게 됩니다(X와 Y를 Mapping 해주는 역할). 때문에 h는 Hypothesis 즉 가정이라는 의미로 주어진 데이터 분포에서 이러한 경향을 보이겠다는 가정을 식으로 나타낸 것입니다.
때문에 h는 데이터 분포를 대표하는 식의 역할을 수행하게 되는데 h를 표현하기 위해 다양한 식이 존재하지만 우선 1차 선형 모델에 대해서 먼저 적어보도록 하겠습니다.
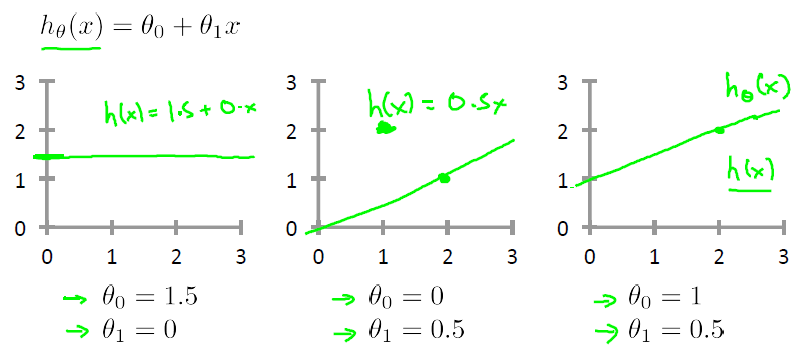
1차 선형모델은 하단의 그림과 같이 y=ax+b라는 1차 함수의 형태로 표현됩니다. 1개의 변수 (x)와 파라미터(theta) 2개로 구성됩니다.
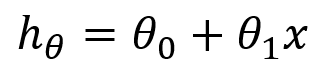
여기서 x는 입력 데이터 (ex - 땅 크기)를 의미하는데 우리가 해줘야 할 일은 바로 주어진 x 데이터들의 경향을 최고로 잘 나타내어주는 theta parameter들을 찾는 게 목적이 되겠습니다. 즉 하단의 그림과 같이 theta 값을 계속 바꾸면서(오른쪽 그림) 별들의 분포를 가장 잘 나타내는 theta를 찾아서 빨간색 선(왼쪽 그림)을 만드는 게 주목적이 되겠습니다.
 |
 |
theta를 잘 찾기 위해서는 현재 잘 찾고 있는가라는 기준 또는 평가지표가 필요합니다. 바로 Cost Function 입니다. Cost의 의미는 비용입니다. 얼마나 잘 찾고 있나를 수치적으로 표현하게 해주는 함수로써 실제와 예측값이 멀리 떨어져 있을수록 Cost가 크게 나타나게 해 줍니다.
대표적인 Cost Function은 예측값(h)과 실제값(y, ex - 집값)의 차이를 제곱하여 표현하는 방법입니다. 제곱의 이유는 차이가 큰것은 더욱 크게 만들고 차이가 작은 것은 (1 이하) 더 작게 만들기 위해서 사용합니다. 그리고 1/2m 같은 경우 m의 의미는 학습 데이터의 개수를 의미하며 2는 계산상 편의를 위해서 사용합니다.

해당 식을 이용하면 예를 들어 theta_0는 0으로 설정하여 원점에서 출발하는 선형모델이라고 생각하였을 때 theta_1만 변하므로 별의 분포를 가장 잘 나타내는 모델인 h_3에서 J(오차)가 제일 작게 나타날 것(오른쪽 그림)입니다.

때문에 정리하면 다음과 같습니다. 가정(모델)에 영향을 미치는 parameter(theta)를 찾아야하는데 학습 데이터와 가장 오차의 제곱이 낮은, 최소화가 되는 Parameter를 찾는 게 바로 학습 데이터를 이용한 학습(Learning)이라고 할 수 있습니다.
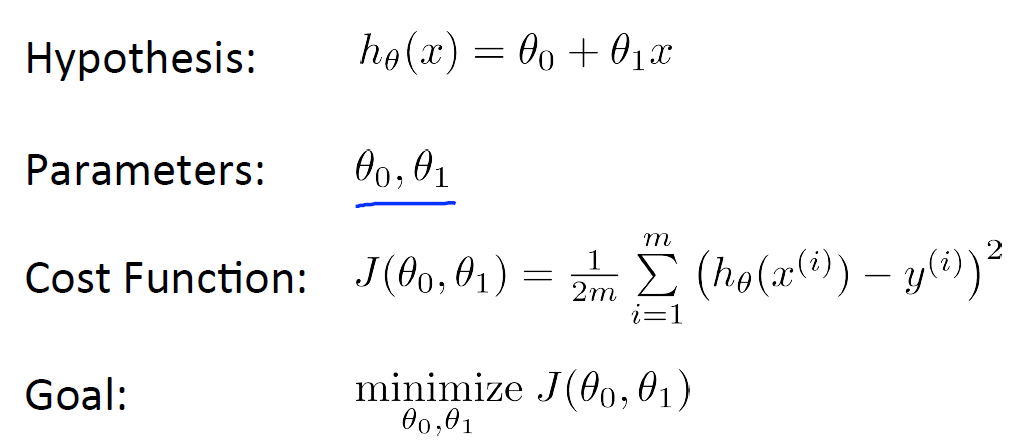
다음 글에서는 J (Cost Function)값의 최소가 되는 지점을 찾아내는 Gradient Descent에 대해서 적어보도록 하겠습니다.
'프로그래밍 ( Programming ) > 머신러닝 ( ML )' 카테고리의 다른 글
| [ML] Logistic Regression 설명 및 직접 구현해보기 (2) | 2021.12.02 |
|---|---|
| [ML] Cross validation(교차 검증)의 개념, 의미 (0) | 2021.11.22 |
| [ML] 뉴런 모델과 퍼셉트론 (perceptron) (0) | 2021.11.22 |
| [ML] 머신러닝 ( Machine Learning ) (0) | 2021.02.07 |
| 경사하강법 (Gradient descent) (0) | 2021.01.23 |




댓글