Logistic Regression (로지스틱 회귀)
로지스틱 회귀 이전에 존재하던 퍼셉트론은 간단하고 좋은 모델이지만 가장 큰 단점은 클래스가 선형적으로 구분되지 않을 때 수렴이 불가능하다는 점입니다.
에포크마다 적어도 하나의 샘플이 잘못 분류되기 때문에 가중치 업데이트가 끝도 없이 계속될수가 있습니다. 물론 학습률을 바꾸거나 에포크 횟수를 늘릴 수는 있지만 한계는 분명 명확하게 존재합니다.
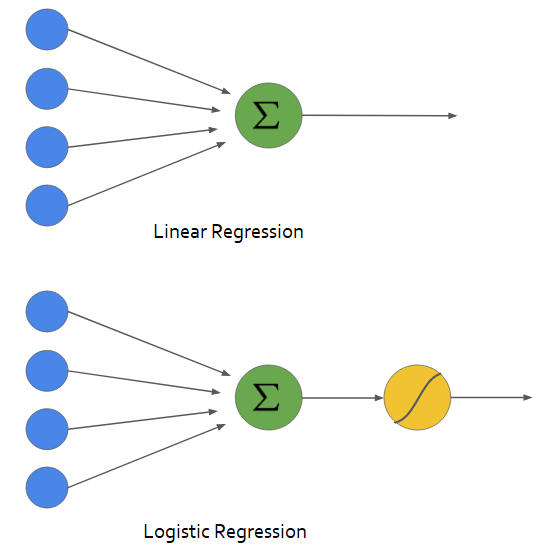
로지스틱 회귀는 이름은 회귀 (Regression)이지만 실제로는 분류 (Classification) 모델입니다.
로지스틱 회귀는 구현이 매우 쉽고 선형적으로 구분되는 클래스에 뛰어난 성능을 내는 분류 모델입니다. 산업계에서 가장 널리 사용되는 분류 알고리즘 중 하나로써 어떤 범주에 속할 확률을 0~1 사이의 값으로 예측하고 더 높은 범주에 속하는 것으로 분류해주는 학습 알고리즘입니다. 예를 들어서 스팸 분류기 또한 spam인지 아닌지를 2개의 범주로 분류는 하는 것을 2진 분류라고 하는데 로지스틱 회귀를 통해 나온 결과를 이용하여 어떤 기준값을 넘거나 넘지 않거나를 통해서 2진 분류가 가능한 알고리즘입니다.
먼저 로지스틱의 아이디어를 설명하기 전에 먼저 오즈비라는것을 설명드리겠습니다.
1. 오즈비 (odds ratio)
오즈는 특정 이벤트가 발생할 확률을 의미합니다. 그리고 오즈비는 오즈를 비율로 나타낸 것으로 공식으로 표현하면 다음과 같습니다. 오즈비는 이벤트가 일어날 확률이 아닐 확률보다 몇 배가 되느냐를 표현한 것으로 예를 들어서 성공할 확률이 0.8일 때 오즈비는 0.8/0.2가 되므로 실패할 확률보다 성공할 확률이 4배이다라는 것을 보여주는 비율입니다. 즉 이를 통해서 성공은 실패 대비 몇 배인가를 한 번에 파악이 가능합니다.
오즈비를 사용하는 이유는 일반적으로 모집단의 크기를 알수없고 우리가 가진 데이터셋, 즉 표본의 크기를 선택하여 성공과 실패의 횟수를 얻을 수 있기에 통계처리 시 많이 이용하게 됩니다. 확률은 변숫값에 의해서 값이 달라집니다. 하지만 오즈비는 확률과는 다른 개념으로 종속변수와 결과 사이의 'constant effect'를 보여줄 수가 있습니다.
*여기서 P는 양성샘플일 확률을 의미합니다. 양성 샘플의 의미는 좋은 것을 의미하지 않고 예측하려는 대상에 대해 의미합니다. 예를 들어서 어떤 환자가 어떤 질병을 가지고 있을 확률을 의미합니다
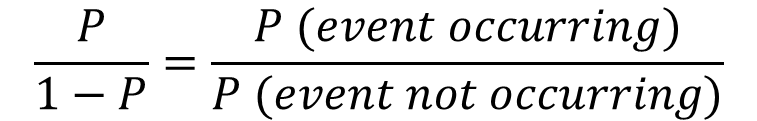
그리고 양성 샘플이 클래스 레이블 y=1이라고 해봅시다.
우리는 로그 (log)를 취해서 log-odds를 만들 수가 있습니다. 보통 log+odds라는 말을 로짓 (logit)이라고도 말합니다.
로짓으로 표현하는 이유는 다음과 같습니다.
y라는 우리의 목표 예측대상이 1과 0이라는 값을 가질 때 마치 선형 회귀분석처럼 아래의 식을 이용하여 계수 추정을 해본다고 생각해봅시다.
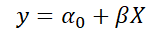
로지스틱 회귀를 이용하여 우리가 예측하고자 하는 y의 범위가 P [Y=1]이라는 믿음을 가지는데 그러기 위해서는 y의 예측값은 0~1 사이로 고정되야합니다. 하지만 위 식의 경우에는 특정 X값에 따라서 y의 예측값이 0~1 사이의 범위를 넘어갈 수가 있습니다.
즉 좌변의 범위는 0~1, 우변의 범위는 (-무한) ~ (+무한)까지의 값을 가지게 되어서 양쪽 변이 서로 다른 범위를 가지고 있는 문제가 있기에 이를 해결하기 위해 로짓 변환을 수행합니다.
로짓 변환을 수행함으로써 우변을 0~1 사이로 만들수가 있는데 로짓 변환은 다음과 같습니다.

좀 더 구체적으로 써보면 다음과 같이 표현이 되며
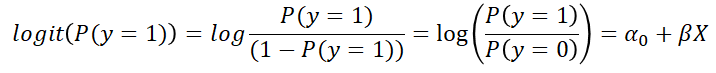
log의 성질을 이용하고 사칙연산을 몇 번 해주시면 우리가 아는 식이 나옵니다.

z라는 변수에다가 값을 아무리 넣어도 우리는 다음과 같은 그래프를 볼 수가 있습니다.
import matplotlib.pyplot as plt
import numpy as np
def sigmoid(z):
return 1.0 / (1.0 + np.exp(-z))
z = np.arange(-7,7,0.1)
phi_z = sigmoid(z)
plt.plot(z,phi_z)
plt.axvline(0.0, color = 'k')
plt.ylim(-0.1,1.1)
plt.xlabel('z')
plt.ylabel('$\phi (z)$')
#y축의 눈금과 격자선
plt.yticks([0.0, 0.5, 1.0])
ax = plt.gca()
ax.yaxis.grid(True)
plt.tight_layout()
plt.show()2. 시그모이드 (Sigmoid) 함수
우리는 이 함수를 시그모이드 (Sigmoid)함수라고 부르며 sigmoid라는 뜻은 2개의 방향으로 가는 curve가 존재하는 모양으로 알파벳의 'S'와 닮아서 지었다고 생각하시면 되겠습니다.
가운데 값이 0.5이며 z값이 무한대로 가면 1에 매우 가까워질 것이며 반대로 음의 무한대로 갈경우 0에 가까워지게 됩니다.
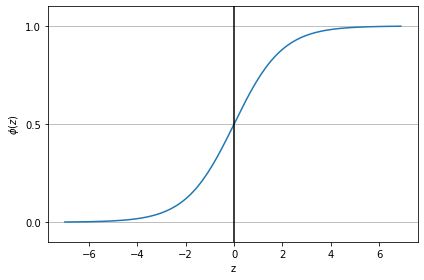
또한 시그모이드함수는 로지스틱 회귀에서 활성화 함수로 사용이 되는데 장점으로는 매우 매끄러운 곡선을 가지기에 경사 하강법을 시행했을 때 기울기가 급격하게 변해서 발산하는 기울기 폭주가 발생하지 않으며 출력 값이 0 또는 1에 어디에 가까운지 쉽게 파악이 가능합니다. 단점으로는 입력값이 아무리 크더라도 출력되는 범위가 좁기에 경사 하강법 수행 시에 범위가 너무 좁아서 0에 수렴하는 기울기 소실 (Gradient Vanishing)이 발생할 수도 있습니다.
이때까지의 이야기를 정리하면 우리는 오즈비라는 아이디어를 이용하고 식에서 우변과 좌변의 범위를 맞춰주기 위해서 로짓으로 변경하여 sigmoid 함수를 만들어 내어서 우리의 예측값들이 0과 1사이에 값으로 표현할 수 있게끔 만들었습니다.
3. Log Loss (로그 손실)
항상 우리는 머신러닝을 수행할때 예측을 제대로 지금 수행하고 있는지 확인을 해야 합니다. 확인을 수행함으로써 적합성을 평가하고 데이터 샘플의 손실을 계산하여 피드백을 수행해주어야 하기 때문입니다. 로지스틱 회귀에서는 확률을 제대로 예측해주는지 확인을 위해서 로그 손실을 사용합니다.
로그 손실의 목표는 로지스틱 함수를 구성하는 계수와 절편에 대해 Log Loss를 최소화하는 값을 찾는 것을 목표로합니다.
우선 로지스틱 회귀 모델을 만들때 최대화하려는 가능도 (Likelihood) L을 정의하겠습니다. 위에서 나왔던 파이를 이용하고 데이터셋에 있는 샘플들이 서로 독립적이라고 가정할 때 공식은 다음과 같습니다.
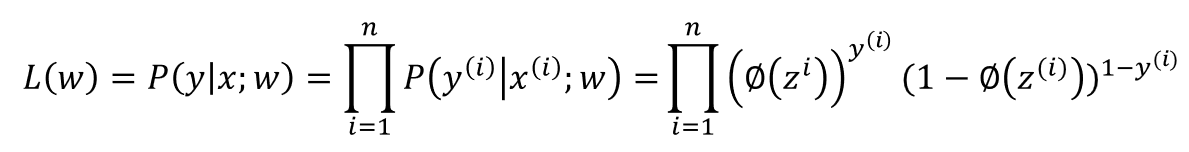
그리고 우리는 (자연)로그를 이용하여 로그 가능도 (Likelihood) 함수를 만들어 줍니다.
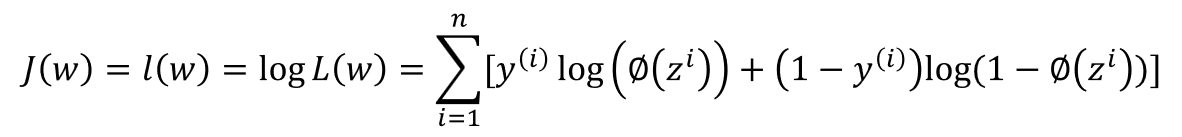
로그함수로 만들어주는 이유는 다음과 같습니다. 첫째로는 로그를 적용시 가능도가 매우 작을 때 일어나는 언더플로우 현상을 미연에 방지할 수가 있습니다. 둘째로는 계수의 곱을 계수의 합으로 바꿀 수 있기에 도함수를 구하기가 쉽습니다.
해당 비용함수를 더 잘 이해하기 위해서 샘플이 하나일 때의 비용을 한번 계산해봅시다. 식에서 n=1이므로 시그마는 사라지게 되며 로지스틱 회귀에서 y=1인가 0인가를 나누는 알고리즘이기 때문에 각각의 경우에 대해 식을 표현하게 되면 상황에 따라서 다음과 같이 변하게 됩니다.
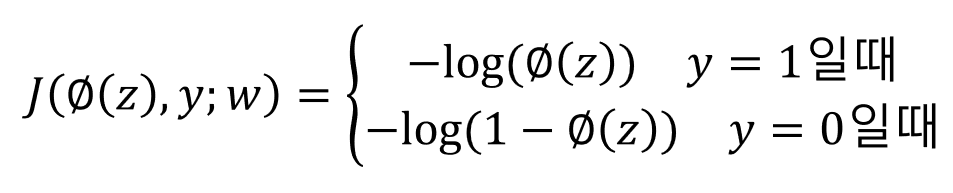
이제 간단한 코드로 샘플이 하나인 경우에 대해 phi값에 따른 비용 그래프를 그려보겠습니다.
def cost_1(z):
return -np.log(sigmoid(z))
def cost_0(z):
return -np.log(1-sigmoid(z))
z = np.arange(-10,10,0.1)
phi_z=sigmoid(z)
c1 = [cost_1(x) for x in z]
plt.plot(phi_z,c1,label='J(w) when y=1')
c0 = [cost_0(x) for x in z]
plt.plot(phi_z,c0,linestyle='--',label='J(w) when y=0')
plt.ylim(0.0, 5.1)
plt.xlim([0, 1])
plt.xlabel('$\phi$(z)')
plt.ylabel('J(w)')
plt.legend(loc='best')
plt.tight_layout()
plt.show()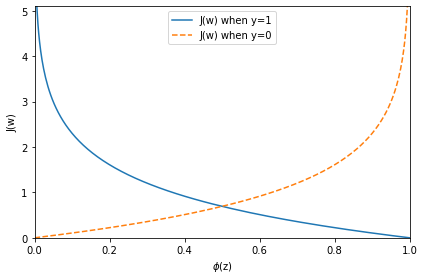
x축은 sigmoid 함수를 통해서 나온 값이며 y축은 로지스틱 비용입니다. 클래스 1에 속한 샘플을 정확하게 예측시예측 시 비용이 0에 가까워지고 (실선) 클래스 0에 속한 샘플을 y=0으로 정확히 예측 시 y축 비용이 0에 가까워지게 됩니다 (점선). 그리고 예측이 잘못될 시 비용은 끝없이 올라가게 되는데 즉 잘못된 예측을 수행할수록 더 큰 비용을 부여하게 되는 시스템입니다.
4. 임계값 (Classfication Threshold)
임계값은 로지스틱 회귀 알고리즘의 결과 값은 분류 확률을 의미하며 어느 수준 이상 확보될 시 특정 클래스에 속할지 말지를 결정하는 값입니다.
당연하게 대부분의 임계값은 0.5이며 필요에 따라서 임계값을 높이거나 낮추어서 민감하게 반응하게 한다던지 또는 둔감하게 반응하여 오분류에 대한 대응을 하기도 합니다.
5. 예제 코드
먼저 1개의 variable만 존재할때를 다뤄봅시다.
순서
- 데이터 준비하기 (x와 y에 대해서 작성 필요, y는 0 또는 1로만 작성)
- sigmoid에 들어갈 임의의 1차 함수 선언하기 (z = Wx + b)
- 손실 함수 & 시그모이드 함수 선언 (이때 손실 함수 계산에서 log(0)이 되는 것을 막기 위해 작은 값을 추가 필요)
- Gradient Descent 알고리즘 작성
- 예측함수, 손실 함수 선언
- 학습률 선언 (알파) - 보통 0.01, 0.001, 0.0001을 이용함, 마무리 (예측 함수, 손실 함수)
(1), (2) 데이터 및 W와 b 준비하기
x가 의미하는게 공부량이라고 생각해봅시다. 그리고 label은 공부량에 따른 합격 (1), 또는 불합격 (0)을 나타냅니다. 그리고 W와 b는 y = Wx+b에서의 알파벳들이며 각각의 사이즈는 1x1 matrix 즉 scalar이기에 random으로 선언해줍니다.
import numpy as np
study = np.array([2, 4, 5, 8, 9, 12, 14, 16, 18, 28]).reshape(10,1)
label = np.array([0, 0, 0, 0, 0, 0, 1, 1, 1, 1]).reshape(10,1)
print("study.shape = ", study.shape, ", label.shape = ", label.shape)
W = np.random.rand(1,1)
b = np.random.rand(1)
print("W = ", W, ", W.shape = ", W.shape, ", b = ", b, ", b.shape = ", b.shape)(3). 시그모이드 함수와 손실 함수 정의
def sigmoid(x):
return 1 / (1+np.exp(-x))
def loss_func(x, t):
delta = 1e-7 #log 무한대 발산 방지
z = np.dot(x,W) + b
y = sigmoid(z)
# cross-entropy
return -np.sum( t*np.log(y + delta) + (1-t)*np.log((1 - y)+delta ) )(4). 경사하강법 알고리즘
def numerical_derivative(f, x):
delta_x = 1e-4 # 0.0001
grad = np.zeros_like(x)
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
idx = it.multi_index
tmp_val = x[idx]
x[idx] = float(tmp_val) + delta_x
fx1 = f(x) # f(x+delta_x)
x[idx] = tmp_val - delta_x
fx2 = f(x) # f(x-delta_x)
grad[idx] = (fx1 - fx2) / (2*delta_x)
x[idx] = tmp_val
it.iternext()
return grad(5). 예측함수, 손실 함수 선언
# 손실함수 값 계산 함수
# 입력변수 x, t : numpy type
def error_val(x, t):
delta = 1e-7 # log 무한대 발산 방지
z = np.dot(x,W) + b
y = sigmoid(z)
# cross-entropy
return -np.sum( t*np.log(y + delta) + (1-t)*np.log((1 - y)+delta ) )
# 학습을 마친 후, 임의의 데이터에 대해 미래 값 예측 함수
# 입력변수 x : numpy type
def predict(x):
z = np.dot(x,W) + b
y = sigmoid(z)
if y >= 0.5:
result = 1 # True
else:
result = 0 # False
return y, result(6). 학습률 선언 (알파) - 보통 0.01, 0.001, 0.0001을 이용함, 마무리
learning_rate = 1e-2 # 발산하는 경우, 1e-3 ~ 1e-6 등으로 바꾸어서 실행
f = lambda x : loss_func(x,label) # f(x) = loss_func(x, label)
print("Initial error value = ", error_val(x, label), "Initial W = ", W, "\n", ", b = ", b )
for step in range(10001):
W -= learning_rate * numerical_derivative(f, W)
b -= learning_rate * numerical_derivative(f, b)
if (step % 400 == 0):
print("step = ", step, "error value = ", error_val(x, label), "W = ", W, ", b = ",b )
결과 검증에 대해서는 임의로 값을 predict 함수를 이용하여 확인을 해보면 됩니다.
(real_val, logical_val) = predict(3)
print(real_val, logical_val) # Fail
(real_val, logical_val) = predict(17)
print(real_val, logical_val) # Success
이제 2개의 variable이 존재할 때를 다뤄봅시다.
순서는 동일하되 데이터를 선언할때가 다릅니다. 이번에 표시하는 x는 학습과 복습 시간을 각각 나타낸 것이고 그에 따른 합격 (1), 불합격 (0)이라고 해보겠습니다. 그리고 W는 2x1 사이즈의 matrix가 되어서 y = (W_1)(x_1) + (W_2)(x_2) +b라는 식의 형태를 만족시킬수있도록 합니다.
# x = (예습시간, 복습시간)
# label = 1 (Pass), 0 (Fail)
import numpy as np
x = np.array([ [2, 4], [4, 11], [6, 6], [8, 5], [10, 7], [12, 16], [14, 8], [16, 3], [18, 7] ])
label = np.array([0, 0, 0, 0, 1, 1, 1, 1, 1]).reshape(9, 1)
# 데이터 차원 및 shape 확인
print("x.ndim = ", x.ndim, ", x.shape = ", x.shape)
print("label.ndim = ", label.ndim, ", label.shape = ", label.shape)
W = np.random.rand(2, 1) # 2X1 행렬
b = np.random.rand(1)
print("W = ", W, ", W.shape = ", W.shape, ", b = ", b, ", b.shape = ", b.shape)
def sigmoid(x):
return 1 / (1+np.exp(-x))
def loss_func(x, t):
delta = 1e-7 # log 무한대 발산 방지
z = np.dot(x,W) + b
y = sigmoid(z)
# cross-entropy
return -np.sum( t*np.log(y + delta) + (1-t)*np.log((1 - y)+delta ) )
def numerical_derivative(f, x):
delta_x = 1e-4 # 0.0001
grad = np.zeros_like(x)
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
idx = it.multi_index
tmp_val = x[idx]
x[idx] = float(tmp_val) + delta_x
fx1 = f(x) # f(x+delta_x)
x[idx] = tmp_val - delta_x
fx2 = f(x) # f(x-delta_x)
grad[idx] = (fx1 - fx2) / (2*delta_x)
x[idx] = tmp_val
it.iternext()
return grad
def error_val(x, t):
delta = 1e-7 # log 무한대 발산 방지
z = np.dot(x,W) + b
y = sigmoid(z)
# cross-entropy
return -np.sum( t*np.log(y + delta) + (1-t)*np.log((1 - y)+delta ) )
def predict(x):
z = np.dot(x,W) + b
y = sigmoid(z)
if y > 0.5:
result = 1 # True
else:
result = 0 # False
return y, result
##########################################################
learning_rate = 1e-2 # 1e-2, 1e-3 은 손실함수 값 발산
f = lambda x : loss_func(x,label)
print("Initial error value = ", error_val(x, label), "Initial W = ", W, "\n", ", b = ", b )
for step in range(80001):
W -= learning_rate * numerical_derivative(f, W)
b -= learning_rate * numerical_derivative(f, b)
if (step % 400 == 0):
print("step = ", step, "error value = ", error_val(x, label), "W = ", W, ", b = ",b )여기도 마찬가지로 결과 검증을 위해서 predict함수를 이용하고 임의의 수를 넣어봅니다.
test_data = np.array([12, 0]) # (예습, 복습) = (12, 0) => Pass (1)
predict(test_data)'프로그래밍 ( Programming ) > 머신러닝 ( ML )' 카테고리의 다른 글
| 몬테 카를로 (Monte Carlo) (2) | 2023.04.20 |
|---|---|
| [ML] Bayesian Optimization이란 (0) | 2021.12.10 |
| [ML] Cross validation(교차 검증)의 개념, 의미 (0) | 2021.11.22 |
| [ML] Linear Regression 선형 회귀 (0) | 2021.11.22 |
| [ML] 뉴런 모델과 퍼셉트론 (perceptron) (0) | 2021.11.22 |




댓글