인공지능은 현재 다양한 산업 문제들을 해결하고 데이터들을 분석하여 최적의 방향으로 나아가게 해주고 있습니다.
인공지능은 말 그대로 사람이 만든 지능입니다. 해당 지능을 수학적 모델에 근거해서 기계에 적용시킴으로써 기계가 학습할 수 있는 능력이 되게 됩니다.
현재 우리가 보고 있는 인터넷에서도 엄청난 머신러닝 기법들이 적용이 되있는데 대표적으로 데이터 마이닝, 즉 대규모로 저장된 데이터 안에서 체계적이고 자동적으로 통계적 규칙이나 패턴을 분석하여 가치 있는 정보를 추출하는 방법입니다. 웹 애플리케이션부터 의학, 생물학, 공학까지 전반에서 적용되어 데이터를 해석하고 있습니다.
또한 과거 2007년에 나온 자율비행을 하는 헬리콥터부터 NLP(자연어 처리), 컴퓨터 비젼과 우리가 자주 사용하는 아마존 넷플릭스 등의 플랫폼에서 사용자의 패턴을 파악하고 어떤 것을 원하는지 추천해주는 서비스까지 확장되고 있습니다.

머신러닝은 그러나 최근에 나온 기술이 아닙니다. 1949년 Hebb이 Hebbian Learning Theory를 발표하는 것으로 시작되었는데요. 이후 1952년에 IBM에서 근무하던 Arthur Samuel은 최초의 머신러닝 프로그램이라 할 수 있는 체커 프로그램을 개발하기도 하였습니다.
Arthur Samuel에 의하면 머신러닝은 "Field of study that gives computers the ability to learn without being explicitly programmed", 즉 명확한 사전 프로그래밍 없이 컴퓨터가 학습할 수 있는 능력에 대한 연구분야라고 하였습니다.
미국 컴퓨터 과학자 Tom Mitchell은 " A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E"라고 언급하였는데 즉 컴퓨터의 학습이라는 것은 어떤 수행해야 할 테스크 T에 관련된 경험들(데이터) E와 그리고 T에 대한 성능을 나타낼 P로 구성이 되는데 P를 통해서 T 수행능력을 평가하고 E를 통해 T를 향상한다는 말을 하였습니다.
예를 들어봅시다. 이메일 프로그램이 있는데 해당 프로그램이 자신한테 오는 메일들중 스팸메일만 구별하고 걸러서 정상적인 메일만 받도록 만들고 싶다고 했을 때 각각의 E, P, T에 대해서 분류를 해보겠습니다.
E(experience)는 경험입니다. 즉 받는 이메일들 중, 스팸으로 분류된 이메일과 정상적인 이메일로 분류된 데이터를 가지고 있는 것입니다.
T(Task)는 수행해야하는 일이기 때문에 이메일 프로그래밍이 경험을 토대로 새 로오는 메일에 대해서 스팸인지 아닌지 구별하는 역할을 의미합니다.
그리고 P(Performance)는 Task를 잘 수행하였는지에 대한 지표로써 예를 들어 한 달 기준으로 받은 스팸메일이 8개이며 걸러지지 못하고 정상적인 이메일로 2개가 분류되었다면 분류 성능은 75%라고 할 수 있습니다.
정리하면 머신러닝은 어떤 데이터를 분류하거나 값을 예측하는 역할을 수행하는데 모두 확률과 통계를 기반으로 시행이 됩니다. 또한 데이터를 잘 분류하기 위해서는 Feature, 즉 특징을 잘 정의를 하는 게 머신러닝의 핵심입니다. 특징이 잘 정의되면 기계는 정확한 답과 특징을 기반으로 유사한 데이터를 알 수가 있기 때문입니다.
머신러닝의 알고리즘은 크게 2가지로 분류될 수 있습니다.
1. Supervised learning : 지도 학습은 이름에서 알 수 있듯이 컴퓨터에게 정답(Label)이 무엇인지 알려주면서 컴퓨터를 학습을 하는 방법입니다.
2. Unsupervised Learning : 지도 학습과는 달리 정답을 알려주지 않고 비슷한 데이터를 군집화 하여 미래를 예측하는 학습 방법입니다.
Supervised Learning( 지도 학습 )의 특징은 기존에 가지고 있는 데이터들 혹은 기준이 되는 데이터를 기반으로 시작됩니다. 크게는 2가지로 분류가 될수있는데 Regression(회귀) 또는 Classification(분류)로 나눌 수 있습니다.
먼저 회귀는 연속적인 데이터들을 기반으로 미래의 값에 대해서 예측을 하는 방법입니다. 대표적으로 예시가 되는 땅의 크기와 집값의 상관 관계를 예로 들어보겠습니다.
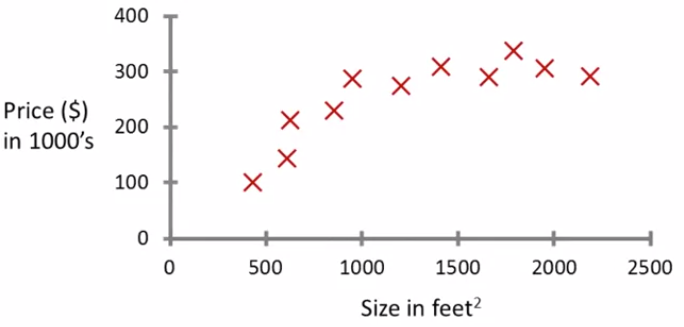
미국의 오리곤주의 데이터로 기존의 데이터들이 현재 x 표시로 그래프에 표기되어 있고 해당 데이터들을 기반으로 만약 750 땅 크기를 가진 데이터가 왔을 때 얼마 정도 할 것인지 예측하는 게 바로 Regression입니다.
두 번째는 분류입니다. 답이 정해져 있는 즉 Label이 있는 데이터를 기반으로 새로운 데이터가 어떤 데이터 그룹에 속하는지 판단하는 알고리즘입니다. 대표적인 예로는 위에서 언급한 스팸 메일 분류로서 새로운 메일이 스팸인지 아닌지 이진 분류 예시 및 하나의 동물이 어떤 동물인지를 맞추는 다중 분류의 예가 있겠습니다.
Unsupervised Learning( 비지도 학습 )은 지도 학습과는 다르게 정답을 따로 알려주지 않고 비슷한 데이터들을 군집화 하는 학습 방법입니다. 예를 들어서 고양이, 병아리 등의 사진을 학습한다고 할 때 각 사진은 무슨 동물인지 답이 주어지지 않습니다. 때문에 동물들을 분류하기 위해서 이 동물이 '무엇이다'라고 명확히 정의는 못하지만 픽셀 데이터나 특징에 기반하여 비슷한 단위로 군집화 하는 학습 방법이 되겠습니다.
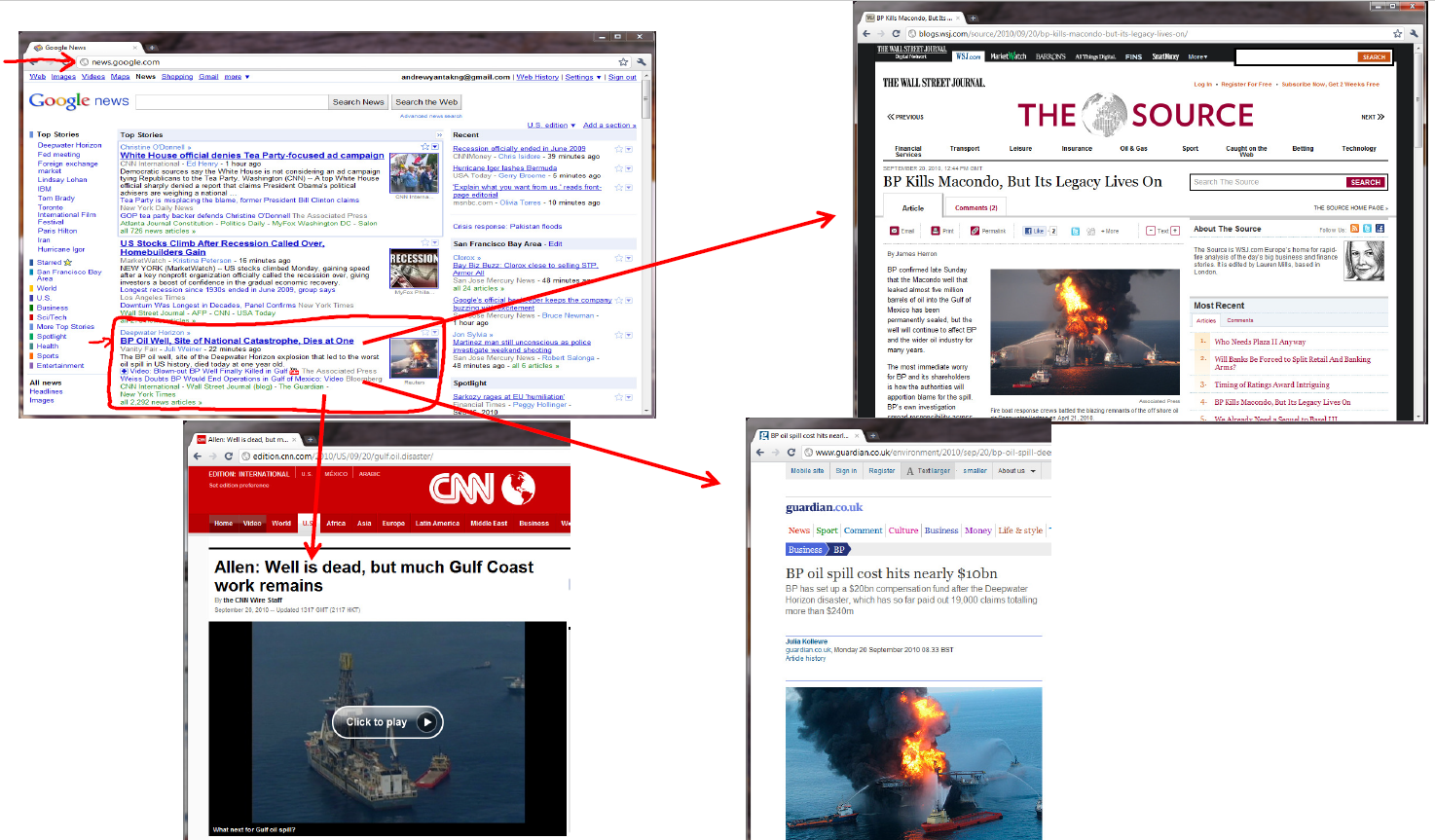
또는 하단의 그림과 같이 기름 사고와 비슷한 기사를 찾는 알고리즘 또한 비지도 학습의 대표적인 예입니다.
'프로그래밍 ( Programming ) > 머신러닝 ( ML )' 카테고리의 다른 글
| [ML] Logistic Regression 설명 및 직접 구현해보기 (2) | 2021.12.02 |
|---|---|
| [ML] Cross validation(교차 검증)의 개념, 의미 (0) | 2021.11.22 |
| [ML] Linear Regression 선형 회귀 (0) | 2021.11.22 |
| [ML] 뉴런 모델과 퍼셉트론 (perceptron) (0) | 2021.11.22 |
| 경사하강법 (Gradient descent) (0) | 2021.01.23 |




댓글